PROJECT: Deadline Manager
This portfolio serves to document my contributions to Deadline Manager - our 2nd year software engineering project. We worked as a team of 5 people to create Deadline Manager, which is based on Address Book (Level 4). We were constrained to use a command line interface (CLI) and were given 6 weeks to work on our application.
Deadline Manager is a desktop deadline manager application designed for students in NUS School of Computing. It is optimized to be easy to use, but yet give users great control and flexibility. It is written in Java. Visit our project page to try our application.
1. Summary of contributions
-
Major enhancement: Added an expressive but terse way to filter tasks.
-
What it does: It allows the user to filter tasks using a filter expression. Filter expressions can be composed from other filter expressions using "AND", "OR", and "NOT" logical operators, and users can optionally specify which attribute in the task to search against.
-
Justification: With an expected large number of tasks in our application, users need to be able to view a subset of tasks that are relevant to them so that they can make sense of their deadlines. The ability to compose filter expressions adds great flexibility which is useful when filtering by more than one field. The ability to export and share tasks further necessitates an expressive filter command that can filter precisely those tasks that the user would like to export.
-
Highlights: Firstly, the implementation features a full expression parser that parses arbitrary levels of parentheses and respects operator precedence. Secondly, many different attribute of a tasks (of varying type, e.g. textual, numeric, date, sets) were made filterable. Thirdly, each attribute could be compared in multiple ways (e.g. users can specify tasks to be filtered if they are due earlier than a given date, later than a given date, or exactly on a given date). Fourthly, text can be quoted in order to search for a whole phrase. Many design considerations have also been made to simplify its use: Specifying the attribute (of the task) for filtering is optional (when unspecified it searches all eligible attributes), a filter expression can use an attribute-specific default comparison, and "AND" operators may be omitted. These design considerations greatly reduce the cognitive burden for simple use cases, but yet retain the ability to provide fine-grained control where needed.
-
-
Minor enhancement: Added the deadline attribute to tasks.
-
What it does: The deadline attribute contains the due date of the task, and this is essential to the core functionality of the deadline manager.
-
Highlights: The implementation deals with the parsing and validating of dates. Furthermore, it integrates into other commands that need to specify a deadline. This attribute was also integrated throughout the storage-related code so that the deadline can be exported to a file and imported into another instance of Deadline Manager.
-
-
Code contributed: CS2103T Project Code Dashboard
-
Other contributions:
-
Project management: Contributed to user stories on GitHub issue tracker (#9, #10, #11, #12, #21, #22); managed milestones on GitHub
-
Enhancements to existing features: Overhauled the existing command parser to use a custom-made string tokenizer shared with the filter expression parser in order to support additional features such as quoted strings. Almost all commands now depend on this string tokenizer.
-
Community:
-
2. Contributions to the User Guide
Given below are excerpts of sections that I contributed to the user guide. They showcase my ability to write documentation targeting end-users. |
2.1. Filtering a list of tasks: filter
Filters the current list of tasks with a specified filter expression.
Format: filter FILTER_EXPRESSION
When this command is used, Deadline Manager will display only those tasks which satisfy the given filter expression.
When executing any modifying commands on a filtered list, the filter will be removed after that command (so all tasks will be shown). Modifying commands are those commands that modify the deadline manager’s content (e.g. add, delete, edit and clear).
|
2.1.1. Overview
Filter predicates are the core of the filter command. Each filter predicate specifies a testable condition that, for every task, may evaluate to either true or false (e.g. whether the deadline is earlier than 1/10/2018). Filter predicates are regarded as "indivisible".
2.1.2. Simplified filter syntax
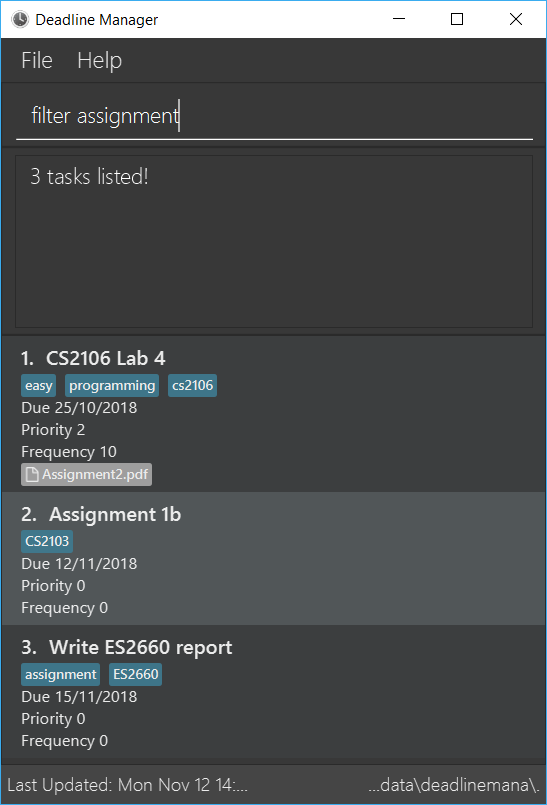
Tasks can be filtered by typing filter followed by one or more space-separated keywords (e.g. filter assignment, filter homework CS2103, or filter badminton utown 3/10/2018). Such a filter expression would display only those tasks that contain textual or date fields (i.e. name, deadline, tags, and attachments) that matches every keyword (e.g. filter homework CS2103 will match a task with name Homework 1 and tags CS2103 and easy).
The screenshot on the right is an example to demonstrate that any field may be matched.
Details of the simplified filter syntax have been omitted for brievity. Please see our user guide for more details and command examples. |
2.1.3. Controlling the field being matched
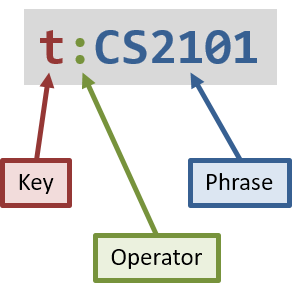
Each keyword can instead be written as a full predicate, which is a string of the following format: <key><operator><phrase>. The diagram on the right is an example of a typical full predicate.
Each of the three parts of a full predicate means the following:
-
keyis an alphabetic string that describes the attribute being compared. For example:priority,tag, orname. -
operatoris one of:,=,<,>. -
phraseis a string that describes what to search (this is called the search phrase, and it is similar to the keyword in the simplified syntax).
The operator : is known as the convenience operator — it is an alias for the operator that intuitively "does what you expect" for the given key.
The behaviour for each given |
2.1.4. Composing filter predicates
Filter predicates may be combined using AND, OR, and NOT operators, as well as any level of parantheses. This feature gives ultimate flexibility to the filter command.
For example, filter n:assignment | (p:3 & t:CS2101) will return a subset of the current list of tasks that have a name that contains "assignment", or have priority at least 3 and contains tag "CS2101".
For more explanation and examples on using composition of filter predicates effectively, please visit our user guide. |
2.1.5. Set-based extensions for filter predicates
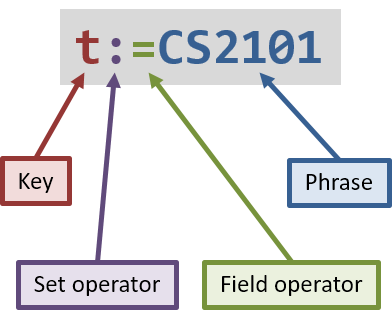
For fields that represent a collection (i.e. tags and attachments), it is also possible to filter only tasks which do not contain other tags or attachments apart from those specified. To do so, we introduce a set operator as per the diagram on the right.
The part that was called operator previously is called the field operator here, and it retains its original meaning. The set operator introduced here specifies how the specified set (in the filter predicate) compares to the task’s set (of tags or attachments).
When comparing a set-based field without using this dual-operator syntax, the set based operator used is effectively the convenience operator. (In other words, <key><operator><phrase> is equivalent to <key>:<operator><phrase>.)
|
Examples to demonstrate each operator type (using the tag field):

| The set operator works in the same way as the above table for the attachment field as well. |
For more examples, please visit our user guide. |
2.1.6. Error messages
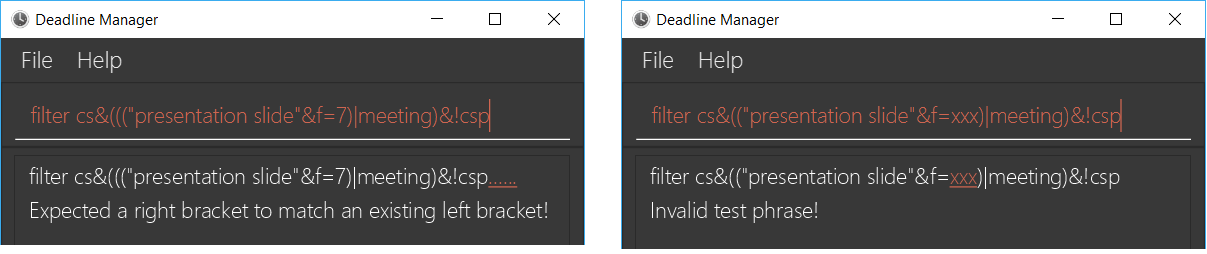
As filter expressions can be made arbitrarily complex, the filter command is also designed to provide comprehensive error messages that will help you to pinpoint any errors.
When an error is encountered, a copy of the filter expression will be displayed, with the error underlined and coloured in red, so that it becomes easier to identify the error. A relevant error message will also be displayed.
| The underlined substring might not always be exactly what you expect, because there could be multiple possible candidates for the error. |
There are a total of around 15 different types of error messages.
The following screenshots show two possible errors and the displayed result:
Many of my contributions to the user guide have been omitted for brevity. Please visit this link for the full user guide. |
3. Contributions to the Developer Guide
Given below are excerpts of sections that I contributed to the developer guide. They showcase my ability to write technical documentation and the technical depth of my contributions to the project. |
3.1. Filter feature
The deadline manager supports a very expressive filtering system. The filtering system can be utilized with the filter command.
3.1.1. Overview
For a more detailed overview of the filter feature, please visit our developer guide. |
There are four components to parsing the filter operation:
-
A boolean expression parser that understands the high-level syntax of the filter expression and digests the filter expression into filter units
-
A parser that splits each filter unit (e.g.
t:CS2101) into its three (or four) constituent parts if possible (e.g.t,:,CS2101) — this is the lambda expression in the sequence diagram below, which resides in theFilterCommandParserclass -
A parser that splits set-based fields (e.g.
CS2101,CS2103) into individual keywords (this applies only to set-based fields (tags and attachments)) — this is referred to as the set parser, and is implemented as a static method in a utility class -
A method for each field (e.g.
Name,Deadline,Priority,Tag) that interprets the parts of the splitted filter unit in the context of that particular field, and returns the predicate that is required — this is referred to as the field-specific parser, and is implemented as a static method in each filterable field
The second component in the list above also accepts a filter unit that contains the third part alone (e.g. CS2101) without the other two parts — this is known as the simplified filter unit syntax. Also, when filtering by a set-based field, the filter unit can be splitted into four parts instead of three (e.g. t=:CS2101,CS2103 will be plitted as t, =, :, CS2101,CS2103), and the additional symbol (= in this case) is used to specify how sets are compared. These will be explained in more detail below.
|
A general string tokenizer (this is the StringTokenizer class in the parser subdirectory) is shared by parts 1 and 2 to split the filter expression into tokens.
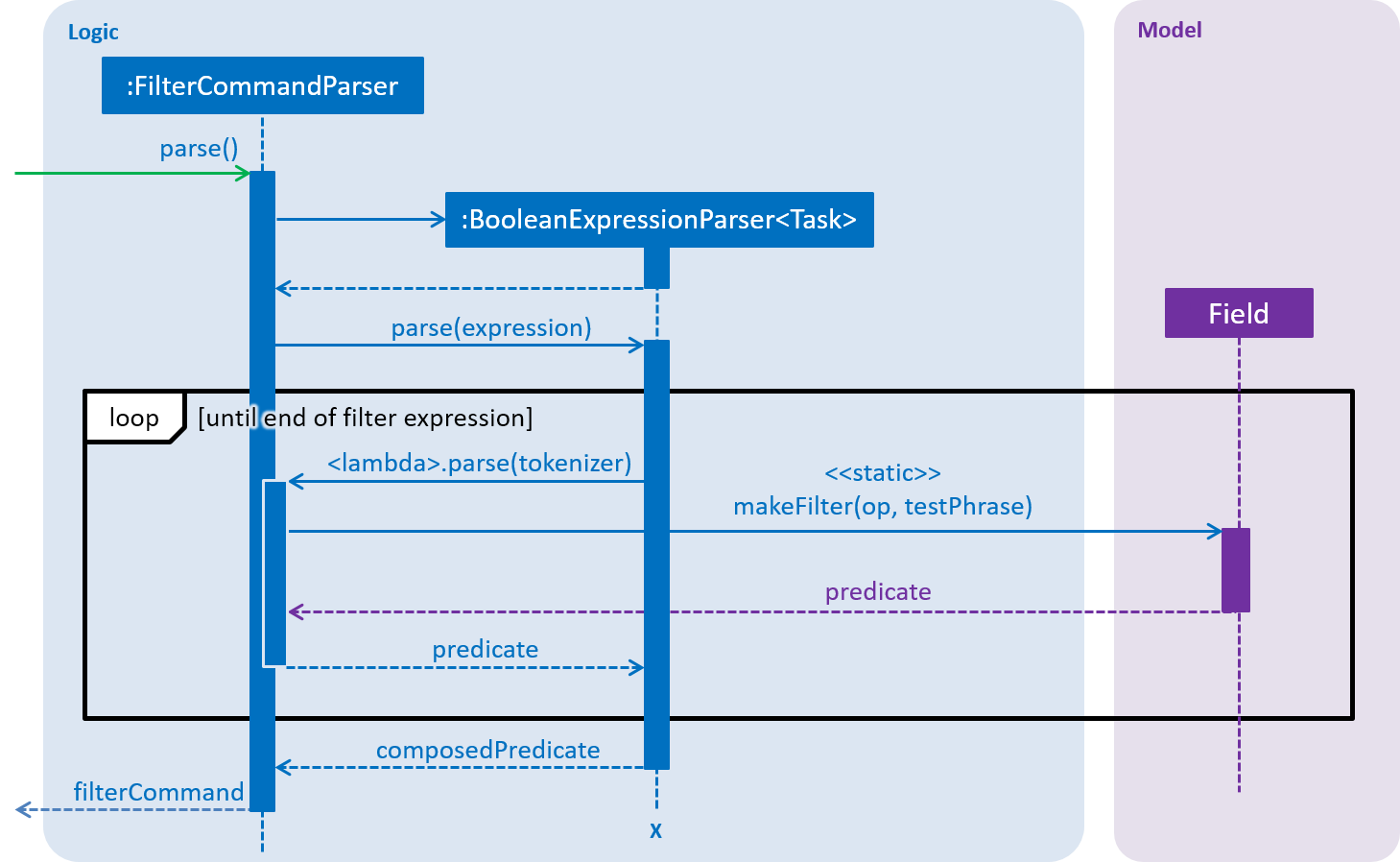
The above diagram shows the simplified sequence of operations to parse a filter expression into a predicate for non-set-based fields. Take note of the following simplifications in the sequence diagram above:
-
"Field" represents any filterable field —
Name,Deadline,Priority, orFrequency. -
Strictly speaking, the "loop" is not actually a loop. As the boolean expression parser parses the filter expression, it invokes the lambda expression whenever a filter unit is encountered. For simplicity, the sequence diagram above hides the complexity within the boolean expression parser.
For more details on the general string tokenizer that was specially designed for the filter command, please visit our developer guide. |
3.1.2. Boolean expression parser
The boolean expression parser uses the shunting yard algorithm to compose NOT, AND, and OR operators, and respects operator precedence. For more information, please visit our developer guide. |
3.1.3. Filter unit parser
The filter unit parser is written as a lambda expression inside the FilterCommandParser class. This lambda expression then calls FilterCommandParser#createFilterUnit, which contains most of the logic for the filter unit parser.
There are three possible ways to express a filter unit:
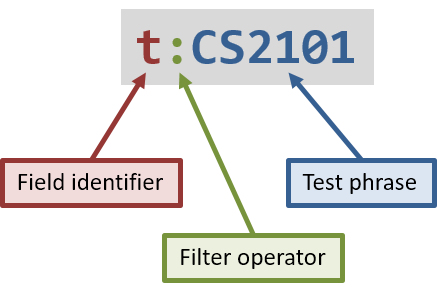
-
The full syntax — this allows for specifying the field for comparison and the method of comparison used
-
The extended full syntax for sets — this is enhanced to specify how to compare sets
-
The simplified syntax — this improves terseness and reduces cognitive overhead
The diagram on the right describes a filter unit that is specified using the full syntax.
The extended full syntax for sets and the simplified syntax are explained in our developer guide. |
The filter unit parser distinguishes between the three possible ways to express a filter unit, as per the activity diagram below:
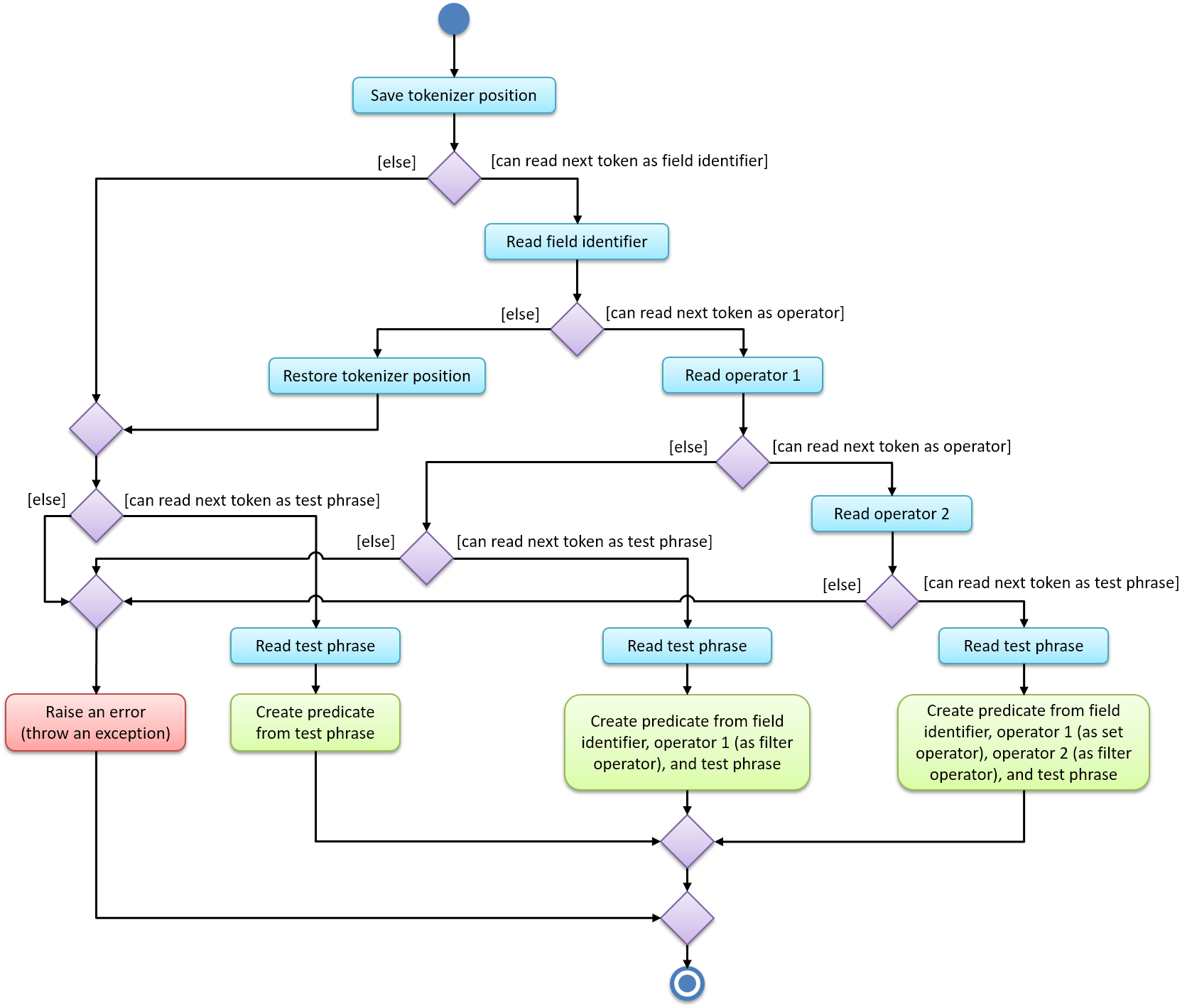
More explanation on the "field identifier", "filter operator", "set operator", and "test phrase" are available in our developer guide. Documentation for the field-specific parser is also available there. Please follow the link for more information. |
3.1.4. Error messages
Error conditions are signalled via checked exceptions that inherit from seedu.address.logic.parser.tokenizer.exception.TokenizationException. Those error conditions that are associated with a particular character range in the filter expression inherit from seedu.address.logic.parser.tokenizer.exception.TokenizationMismatchException, which provides the facilities for storing the start and end indices of the offending character range. TokenizationMismatchException itself inherits from TokenizationException. Checked exceptions were chosen because they allow the compiler to enforce that every possible exception is caught, and creating a subclass for each kind of error condition allows for the precise specification (in the throws clause) of the kind of error conditions that can happen in each and every method.
The following inheritance diagram shows the inheritance hierarchy of each kind of exception that can be thrown from parsing a filter expression:
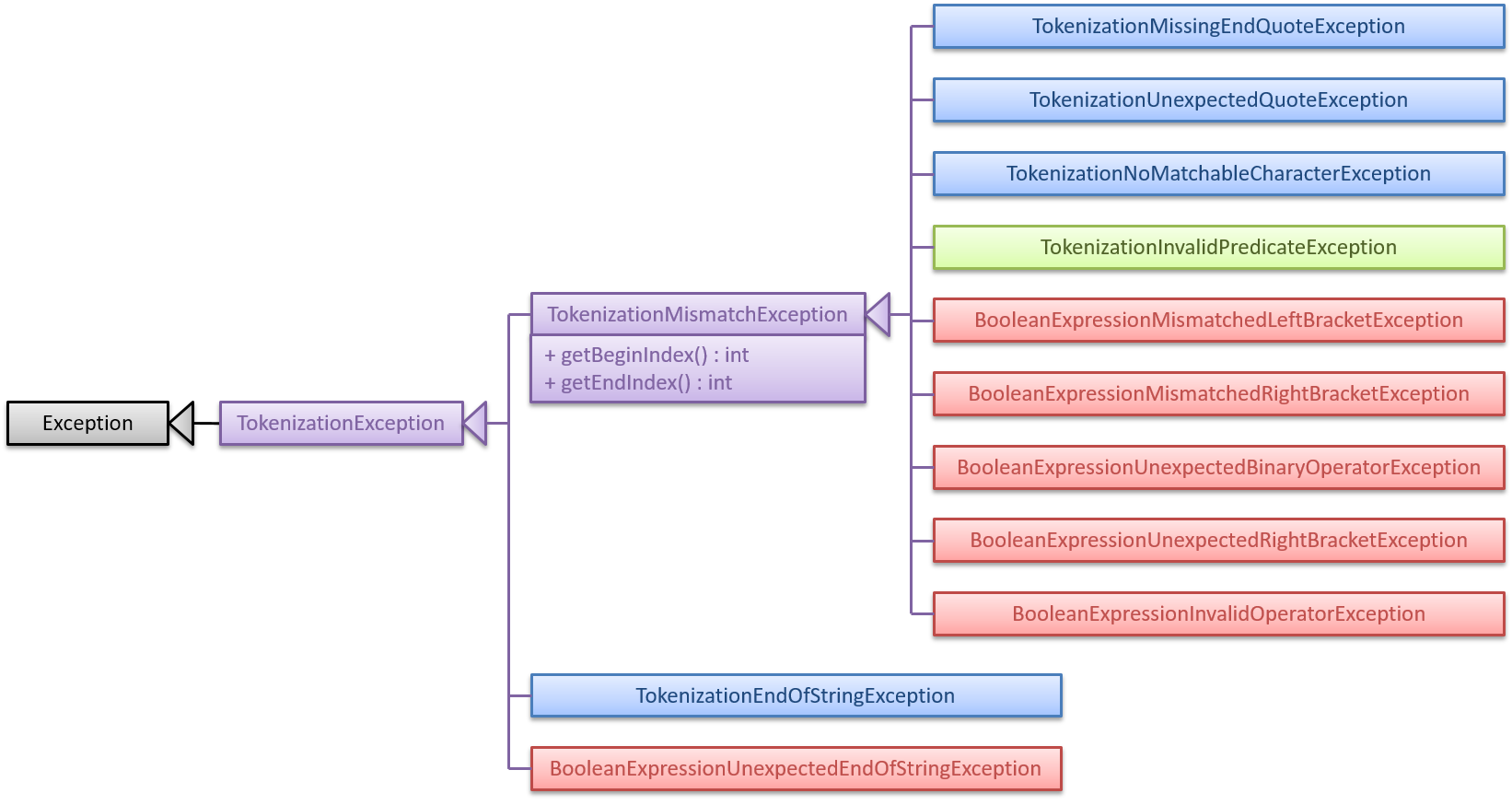
In the diagram above, the blue classes are exceptions thrown by StringTokenizer, while the red classes are exceptions thrown by BooleanExpressionParser.
More explanation on the use of |
3.1.5. Design Considerations
3.1.5.1. Aspect: What the convenience operator should do
-
Alternative 1 (current choice): Support a convenience operator that is an alias of the most common filter operator for each field.
-
Pros: Reduces cognitive overhead as the convenience operator is usually the expected behaviour for most applications.
-
Cons: Users might be surprised that the convenience operator is an alias for a different operator depending on the field identifier.
-
-
Alternative 2: Support a convenience operator that is an alias of a fixed operator regardless of field.
-
Pros: Easier for users to remember what the convenience operator does.
-
Cons: Convenience operator is not really convenient — the behaviour might be surprising or awkward for some fields.
-
3.1.5.2. Aspect: How to signal exceptional conditions when parsing filter expressions
-
Alternative 1 (current choice): Use a different type of checked exception for every possible type of failure condition.
-
Pros: Every possible failure condition is listed in the
throwsclause of all methods — developers can easily tell how exactly each aspect of parsing could fail, and Java will statically check that every possible failure condition is handled (which makes it impossible to overlook any failure conditions). -
Cons: More verbose method signatures.
-
-
Alternative 2: Use a single checked exception for all possible failure conditions, and distinguish errors by the message string instead.
-
Pros: Less verbose method signatures, and yet the benefit of checked exceptions is retained.
-
Cons: Developers can only tell what exact failure conditions are possible by inspecting the whole call graph of the method. Furthermore, it is difficult to distinguish different error conditions in order to customize and show relevant messages to the user.
-
-
Alternative 3: Use unchecked exceptions.
-
Pros: Simplest method signatures.
-
Cons: Easy to overlook possible failure conditions when modifying the code, so future developers might inadvertently introduce bugs.
-
Many of my contributions to the developer guide have been omitted for brevity. Please visit this link for the full developer guide. |